Like in other programming languages i.e., C, C++, JAVA,etc., we learn a basic program called "Hello World", on the same ground, in Hadoop, there is a basic program named "Word Count", which uses both Map and Reduce concept.
Important Note: In Hadoop context, whenever we execute the
hadoop jar <JAR File name> <DriverClassNameWithoutExtension> <HDFS Input Path> <Hadoop Output Path>
we have to make sure that HDFS output path should not exist beforehand.
To avoid this situation, the same thing is handled as a part of Driver code, where, if the output folder is already present in HDFS, it will be deleted first and then the processing will start.
The program is explained in detailed manner as below:
Requirement:
Inputfile.txt contains following data
Inputfile.txt
------------------------------------------------------------------------------------------------
Hadoop is a big data analytics tool.
Hadoop has different components like MapReduce, Pig, hive, hbase, sqoop etc.
MapReduce is used for processing the data using Java.
-------------------------------------------------------------------------------------------------
We have to count the number of occurrences of each word in the file.
If there is same word, but change is in case(uppercase/lowercase) format, then it will consider as different words.
E.g., Hadoop and hadoop are considered as different words are per the logic implemented.
So the Output should be as below:
| Hadoop |
2 |
| is |
4 |
| a |
1 |
| big |
1 |
| data |
2 |
| analytics |
1 |
| tool. |
1 |
| has |
1 |
| different |
1 |
| components |
1 |
| like |
1 |
| MapReduce, |
1 |
| Pig, |
1 |
| hive, |
1 |
| hbase, |
1 |
| sqoop |
1 |
| etc. |
1 |
| MapReduce |
1 |
| for |
3 |
| processing |
1 |
| the data |
1 |
| using |
1 |
| Java. |
1 |
Logic being used in Map-Reduce
There may be different ways to count the number of occurrences for the words in the text file, but Map reduce uses the below logic specifically.
Input
Hadoop is a big data analytics tool.
Hadoop has different components like MapReduce, Pig, hive, hbase, sqoop etc.
MapReduce is used for processing the data using Java.
Input to Mapper
1010L Hadoop is a big data analytics tool.
1012L Hadoop has different components like MapReduce, Pig, hive, hbase, sqoop etc.
1013L MapReduce is used for processing the data using Java.
After the Mapper phase
Fetch the each word and assign the 1. It indicates that Mapper found each word once.
| Hadoop |
1 |
| is |
1 |
| a |
1 |
| big |
1 |
| data |
1 |
| analytics |
1 |
| tool. |
1 |
| Hadoop |
1 |
| has |
1 |
| different |
1 |
| components |
1 |
| like |
1 |
| MapReduce, |
1 |
| Pig, |
1 |
| hive, |
1 |
| hbase, |
1 |
| sqoop |
1 |
| etc. |
1 |
| MapReduce |
1 |
| is |
1 |
| used |
1 |
| for |
1 |
| processing |
1 |
| the |
1 |
| data |
1 |
| using |
1 |
| Java. |
1 |
After Reducer Phase
Gets the similar word from Mapper output and sum it up.
| Hadoop | 2 |
| is | 2 |
| a | 1 |
| big | 1 |
| data | 2 |
| analytics | 1 |
| tool. | 1 |
| has | 1 |
| different | 1 |
| components | 1 |
| like | 1 |
| MapReduce, | 1 |
| Pig, | 1 |
| hive, | 1 |
| hbase, | 1 |
| sqoop | 1 |
| etc. | 1 |
| MapReduce | 1 |
| for | 1 |
| processing | 1 |
| the data | 1 |
| using | 1 |
| Java. | 1 |
which is the
final output, having count of each word in the input file.
The program has each and every details, so that even a newbie in Java can write the Wordcount program
Note: I am using Java 1.6 and eclipse Helios, for this development.
For Hadoop, Java 1.6 is minimum requirement. We can use any flavor of eclipse for Hadoop development.
- Open Eclipse, for creating the Java project.
- Go to File->New->Java Project
- Enter the name in Project Name. I used WordCountDemoApp as name to my Word count Java project.
- Click Finish,
- Go to Project Explorer. You will notice that WordCountDemoApp is created as the project, with subfolders namely src and JRE System Library [jre6]
- Right click on src folder and select New->Class.
- Enter the Package Name as MapReduceWordCount(optional), Name of the Main class as WordCount (mandatory) and tick the checkbox for "public static void main(String[] args)"
Copy the below code in the eclipse.
Detailed comments has been added in the code for each line.
package MapReduceWordCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/*Driver class*/
public class WordCount {
// Class for Mapper, to convert the string into tokens
/*
* e.g., I/P - Hadoop is big data tool, which is good for data analytics
*/
/*
* O/P - Hadoop - 1 is - 1 big - 1 data - 1 tool - 1 which - 1 is - 1 good -
* 1 for - 1 data - 1 analytics - 1
*/
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
// Constant variable for 1
private final static IntWritable ONE = new IntWritable(1);
// Declaring word variable of type Text
private final Text word = new Text();
// Overrided function from Mapper class
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// Fetching each line from the file into tokens(words) separated by
// SPACE and COMMA
StringTokenizer str = new StringTokenizer(value.toString(), " ");
// Running the below loop till EOF of the current file
while (str.hasMoreTokens()) {
// Set the word with the next available token
word.set(str.nextToken());
//
// Use below line of code instead of above, if want to recognize
// hadoop and Hadoop as same word. Converting all words to
// lowercase before writing it to context....
// word.set(str.nextToken().toLowerCase());
// Write the K, V into context
context.write(word, ONE);
}
}
}
// Class for Reducer, to count the words from each Mapper's output
/*
* e.g., I/P -> Hadoop - 1 is - 1 big - 1 data - 1 tool - 1 which - 1 is - 1
* good - 1 for - 1 data - 1 analytics - 1
*/
/*
* O/P -> Hadoop - 1 is - 2 big - 1 data - 1 tool - 1 which - 1 good - 1 for
* - 1 data - 1 analytics - 1
*/
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
// variable to store the result
IntWritable result = new IntWritable();
// Press Ctrl - 3 and type 'override' to get the overrided methods
// Overrided function from Reducer class
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
// initializing the sum to 0
int sum = 0;
/*
* Using foreach loop iterating through all the Mapper output to
* count the words
*/
for (IntWritable value : values) {
sum = sum + value.get();
}
/* Set the result with sum value */
result.set(sum);
/* Write the K,V into context */
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, Exception {
// Configutation details w. r. t. Job, Jar file
/* Provides access to configuration parameters */
Configuration conf = new Configuration();
/* Creating the job object for the Hadoop processing */
Job job = new Job(conf, "WORDCOUNTJOB");
/* Creating Filesystem object with the configuration */
FileSystem fs = FileSystem.get(conf);
/* Check if output path (args[1])exist or not */
if (fs.exists(new Path(args[1]))) {
/* If exist delete the output path */
fs.delete(new Path(args[1]), true);
}
// Setting Driver class
job.setJarByClass(WordCount.class);
// Setting the Mapper class
job.setMapperClass(TokenizerMapper.class);
// Setting the Combiner class
job.setCombinerClass(IntSumReducer.class);
// Setting the Reducer class
job.setReducerClass(IntSumReducer.class);
// Setting the Output Key class
job.setOutputKeyClass(Text.class);
// Setting the Output value class
job.setOutputValueClass(IntWritable.class);
// Adding the Input path
FileInputFormat.addInputPath(job, new Path(args[0]));
// Setting the output path
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// System exit strategy
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Adding Dependent JAR files for Hadoop
Below are the 2 jar files which are required for this development.
- hadoop-ant-0.20.2-cdh3u5.jar
- hadoop-core-0.20.2-cdh3u5.jar
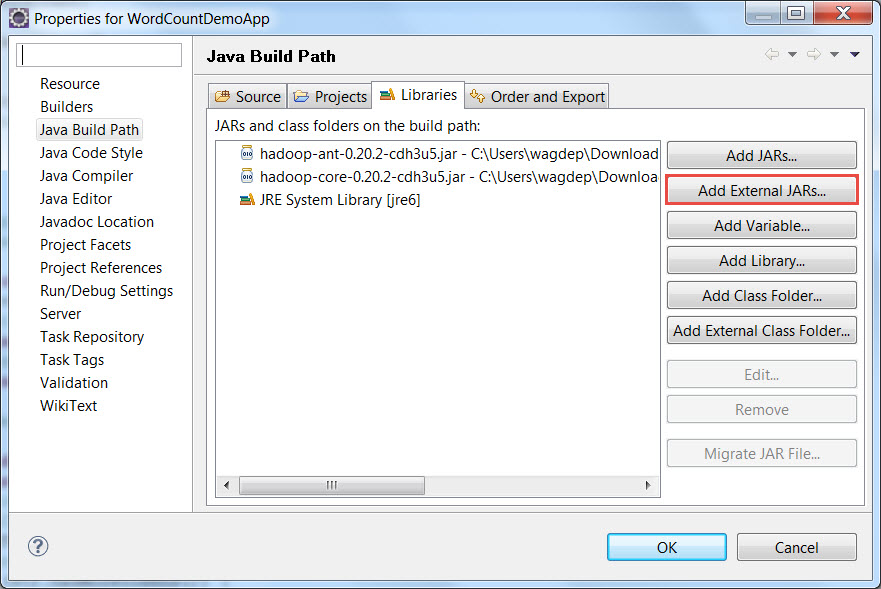
Process to add dependent JARs in eclipse
- Right click on the Project WordCountDemoApp
- Go to Build Path | Configure Build Path..
- Click Add External JARs...
- Browse the folder and select the required JARs and Click OK.
How to create the JAR file?
- Right click on the project ( MapReduceWordCount in this case)
- Click Export.
- Select JAR file option from the list. Click Next.
- Select the Project correctly and specify the path on which JAR file should be created.
- Click Next.
- Click Next.
- Keep Main Class empty. Do not specify anything in Main Class
- Click Finish.
Execution steps
- Copy the Jar file to the appropriate location in LFS in hadoop.
- Go to that location/ path and type the command as below
The above command will give the details of the classes i.e, Mapper class(TokenizerMapper), Reducer class(IntSumReducer) and Driver class(WordCount).
Finally at the same path, type the below command..
Command is
#hadoop jar <RunnableJARName> <DriverClassNameWithout extension> <HDFSInputPathWithFilesName(s)> < HDFSOutputPath>
Input file:
Final Output